Setup
Graylog Archive is a commercial feature that can be installed in addition tothe Graylog open source server.
Installation
Archiving is part of the Graylog Enterprise plugin, please check the Graylog Enterprise setup page for details onhow to install it.
Configuration
Graylog Archive can be configured via the Graylog web interface and doesnot need any changes in the Graylog server configuration file.
In the web interface menu navigate to “Enterprise/Archives” and click “Configuration”to adjust the configuration.
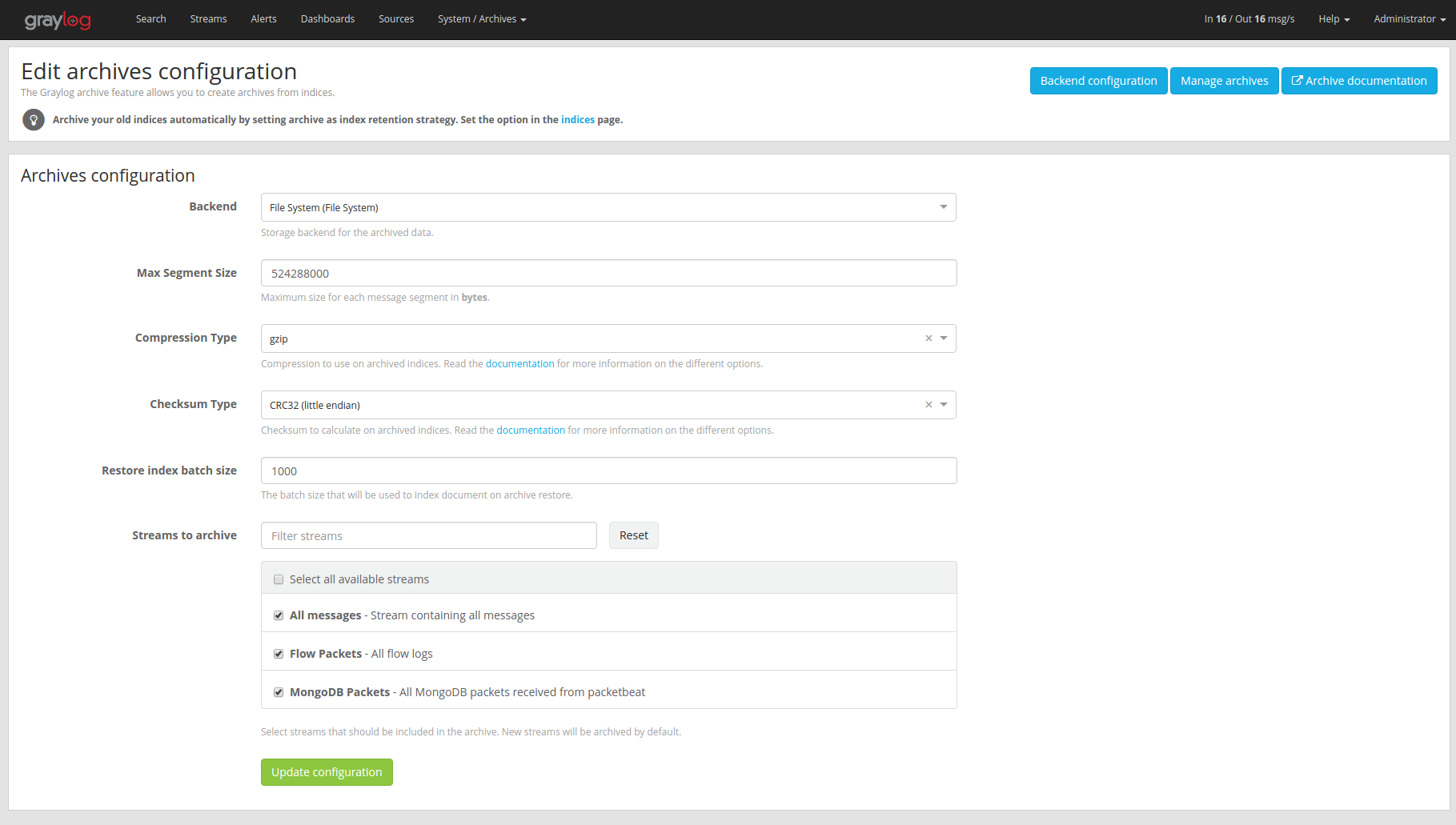
Archive Options
There are several configuration options to configure archiving.
Configuration Options
| Name | Description |
|---|---|
| Backend | Backend on the master node where the archive files will be stored. |
| Max Segment Size | Maximum size (in bytes) of archive segment files. |
| Compression Type | Compression type that will be used to compress the archives. |
| Checksum Type | Checksum algorithm that is used to calculate the checksum for archives. |
| Restore index batch size | Elasticsearch batch size when restoring archive files. |
| Streams to archive | Streams that should be included in the archive. |
Backends
The archived indices will be stored in a backend. You can choose from two types:
- File system
- S3
File System Backend
A backend that stores the data in /tmp/graylog-archiveis created when the server starts for the firsttime but you can create a new backend if you want to store the data in a different path.
S3 Archiving Backend
The S3 Archiving backend can be used to upload archives to an AWS S3 object storage service. It is built to workwith AWS, but should be compatible with other S3 implementations like MinIO, CEPH, Digital Ocean Spaces, etc.
On the Archive page:
- Click the Manage Backends button on the top right.
- Click Create Backend under the Archive Backends ; this takes you to Edit archive backend configuration options .
- Go to the Backend configuration section and on the Backend Type dropdown select S3 .
- Fill out the form, completing the fields that best suit your choice of archive.
| Name | Description |
|---|---|
| Title | A simple title to identify the backend |
| Description | Longer description for the backend |
| S3 Endpoint URL | Only configure this if not using AWS |
| AWS Authentication Type | Choose access type from the dropdown menu |
| AWS Assume Role (ARN) | This is an optional input foralternate authentication mechanisms |
| Bucket Name | The name of the S3 bucket |
| Spool Directory | Directory where archiving data is storedbefore being uploaded |
| AWS Region | Choose Automatic or configure theappropriate option |
| S3 Output Base Path | Archives will be stored under this path |
AWS Authentication Type
Graylog provides several options for granting access. You can:
- use the Automatic authentication mechanism if you provide AWS credentials through your filesystem or process environment.
- enter credentials manually
AWS Assume Role (ARN)
This is typically used for allowing cross-account access to a bucket. See ARN for further details.
Spool Directory
The archiving process needs this directory to store some temporary data, before it can beuploaded to S3.
This directory should be writable and have enough space to fit 10 times the Max Segment Size .You can make adjustments in the form mentioned in Configuration .
AWS Region
Select the AWS region where you archiving bucket resides in. If none is selected, Graylog triesto get the region from your file system or process environment.
If you are not using AWS, you do not need to configure this.
S3 Output Base Path
This is a prefix to the file name that works similar to a directory. Configuring this willhelp you organize data.
You can use the following variable to construct a dynamic value for each archive to giveit structure:
| variable | Description |
|---|---|
| index-name | Name of the index that gets archived |
| year | Archival date year |
| month | Archival date month |
| day | Archival date day |
| hour | Archival date hour |
| minute | Archival date minute |
| second | Archival date second |
Activate Backend
After configuring your bucket, click Save .
This will bring you back to the Edit archive backend configuration page.
To activate the backend, you need to:
- Click on the Configuration tab located in the top righthand corner.
- Under the Backend dropdown menu, select the backend you want to activate.
- You can choose to change configurations or use the defaults provided.
- Click the green Update configuration button at the bottom of the screen.
- This will return you to the Archives screen.
Max Segment Size
When archiving an index, the archive job writes the data into segments.The Max Segment Size setting sets the size limit for each of these datasegments.
This allows control over the file size of the segment files to make itpossible to process them with tools which have a size limit for files.
Once the size limit is reached, a new segment file will be started.
Example:
/path/to/archive/
graylog_201/
archive-metadata.json
archive-segment-0.gz
archive-segment-1.gz
archive-segment-2.gz
Compression Type
Archives will be compressed with gzip by default. This option can be changed to use a different compression type.
The selected compression type has a big impact on the time it takes to archive an index. Gzip for example is prettyslow but has a great compression rate. Snappy and LZ4 are way faster but the archives will be bigger.
Here is a comparison between the available compression algorithms with test data.
Compression Type Comparison
| Type | Index Size | Archive Size | Duration |
|---|---|---|---|
| gzip | 1 GB | 134 MB | 15 minutes, 23 seconds |
| Snappy | 1 GB | 291 MB | 2 minutes, 31 seconds |
| LZ4 | 1 GB | 266 MB | 2 minutes, 25 seconds |
Note
Results with your data may vary! Make sure to test the different compression typesto find the one that is best for your data.
Warning
The current implementation of LZ4 is not compatible with the LZ4 CLI tools, thus decompressing the LZ4 archives outside of Graylog is currently not possible.
Checksum Type
When writing archives Graylog computes a CRC32 checksum over the files. This option can be changed to use a different checksum algorithm.
The type of checksum depends on the use case. CRC32 and MD5 are quick to compute and a reasonable choice to be able to detect damaged files, but neither is suitable as protection against malicious changes in the files.Graylog also supports using SHA-1 or SHA-256 checksums which can be used to make sure the files were not modified, as they are cryptographic hashes.
The best choice of checksum types depends on whether the necessary system tools are installed to compute them later (not all systems come with a SHA-256 utility for example), speed of checksum calculation for larger files as well as the security considerations.
Restore Index Batch Size
This setting controls the batch size for re-indexing archive data intoElasticsearch. When set to 1000, the restore job will re-index thearchived data in document batches of 1000.
You can use this setting to control the speed of the restore process and alsohow much load it will generate on the Elasticsearch cluster. The higher the batch size, the faster the restore will progress and the more loadwill be put on your Elasticsearch cluster in addition to the normal message processing.
Make sure to tune this carefully to avoid any negative impact on yourmessage indexing throughput and search speed!
Streams To Archive
This option can be used to select which streams should be included in thearchive. With this you are able to archive only your important data insteadof archiving everything that is arriving in Graylog.
Note
New streams will be archived automatically. If you create a new streamand don’t want it to be archived, you have to disable it in thisconfiguration dialog.
Backends
A backend can be used to store the archived data. For now, we only support a single file system backend type.
File System
The archived indices will be stored in the *Output base path* directory. Thisdirectory **needs to exist and be writable for the Graylog server process** so the filescan be stored.Note
Only the master node needs access to the Output base path directory because the archiving process runs on the master node.
We recommend to put the Output base path directory onto a separate disk or partition to avoidany negative impact on the message processing should the archiving fill upthe disk.
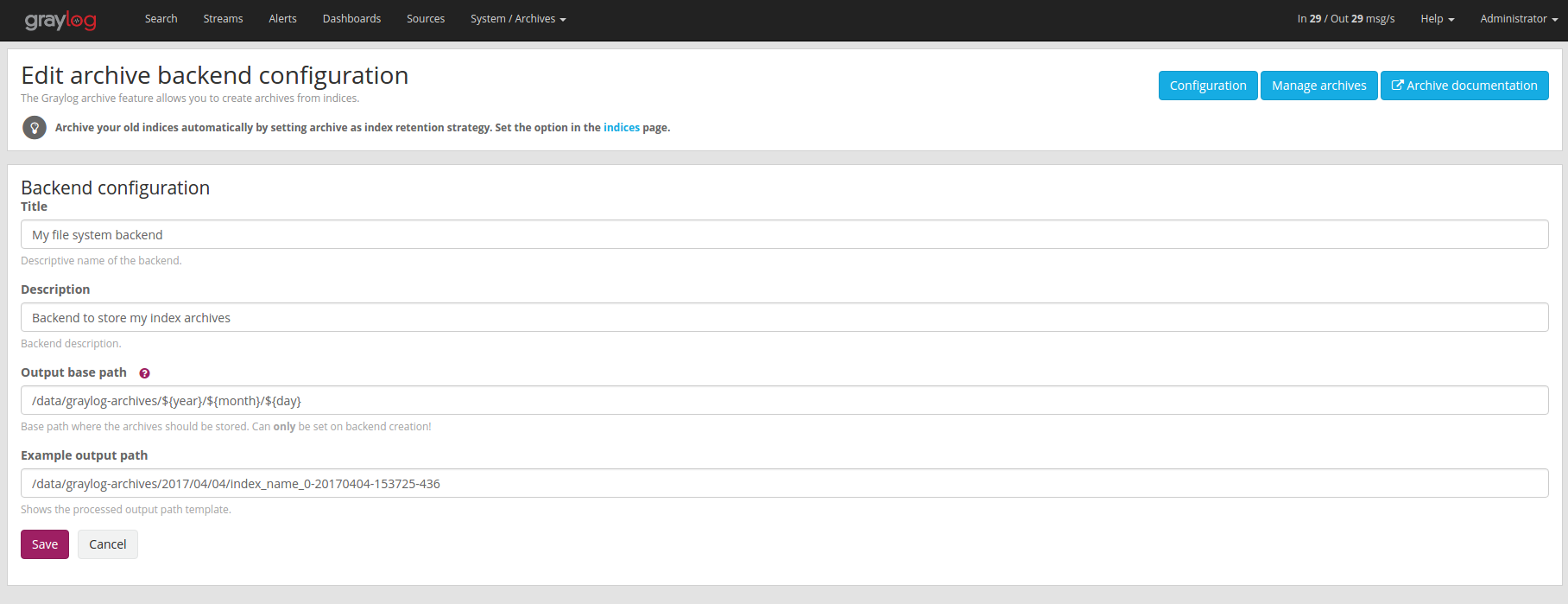
Configuration Options
| Name | Description |
|---|---|
| Title | A simple title to identify the backend. |
| Description | Longer description for the backend. |
| Output base path | Directory path where the archive files should be stored. |
Output base path
The output base path can either be a simple directory path string or a template string to build dynamic paths.
You could use a template string to store the archive data in a directory tree that is based on the archival date.
Example:
# Template
/data/graylog-archive/${year}/${month}/${day}
# Result
/data/graylog-archive/2017/04/01/graylog_0
Available Template Variables
| Name | Description |
|---|---|
${year} | Archival date year. (e.g. “2017”) |
${month} | Archival date month. (e.g “04”) |
${day} | Archival date day. (e.g. “01”) |
${hour} | Archival date hour. (e.g. “23”) |
${minute} | Archival date minute. (e.g. “24”) |
${second} | Archival date second. (e.g. “59”) |
${index-name} | Name of the archived index. (e.g. “graylog_0”) |
Index Retention
Graylog is using configurable index retention strategies to delete oldindices. By default indices can be closed or deleted if you have morethan the configured limit.
Graylog Archive offers a new index retention strategy that you can configure toautomatically archive an index before closing or deleting it.
Index retention strategies can be configured in the system menu under“System/Indices”. Select an index set and click “Edit” to change the index rotationand retention strategies.
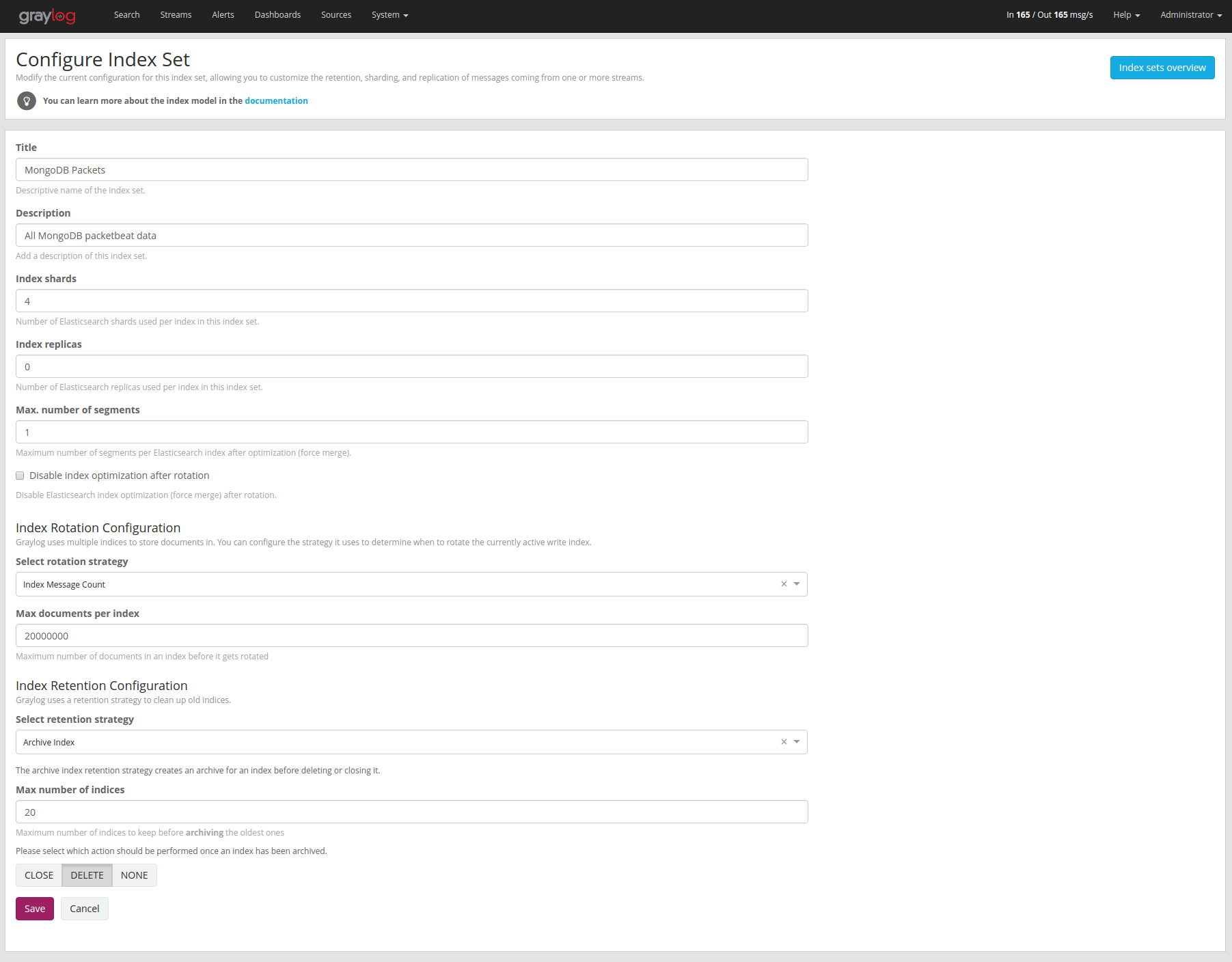
As with the regular index retention strategies, you can configure a maxnumber of Elasticsearch indices. Once there are more indices than theconfigured limit, the oldest ones will be archived into the backend andthen closed or deleted. You can also decide to not do anything (NONE ) afterarchiving an index. In that case no cleanup of old indices will happen and you have to take care of that yourself!